The Problem
Most teams on AWS have a backup strategy. What they often lack is evidence that the backup actually works. A recovery point existing in a vault is a necessary condition for recovery — it is not a sufficient one.
Infrastructure drifts. A subnet group gets deleted. An IAM role loses a permission. A KMS key rotates. None of these events invalidate the backup job — the recovery point still exists, the backup console still shows green — but any one of them can silently break the restore. The only way to know is to try the restore.
Manual restore testing is the traditional answer, but it scales poorly. Coordinating teams, running through a checklist, validating the result — it happens quarterly at best. Three months of infrastructure drift is a long time to be flying blind on DR.
AWS Backup Restore Testing closes this gap. It automates the full restore-validate-report cycle on a schedule, producing a continuous auditable signal that recovery points are actually restorable — not just created. The same trail satisfies evidence requirements for SOC 2, ISO 27001, NYDFS, and EU DORA.
In this post I walk through the architecture I built in ap-southeast-1: a nightly backup plan for an RDS instance and an S3 bucket, wired to a restore testing plan that drives an EventBridge → Lambda validation pipeline and reports results back to the AWS Backup console.
Architecture & Data Flow
The system runs as two independent halves joined by a single shared store — the backup vault. Phase 1 writes to it; Phase 2 reads from it.
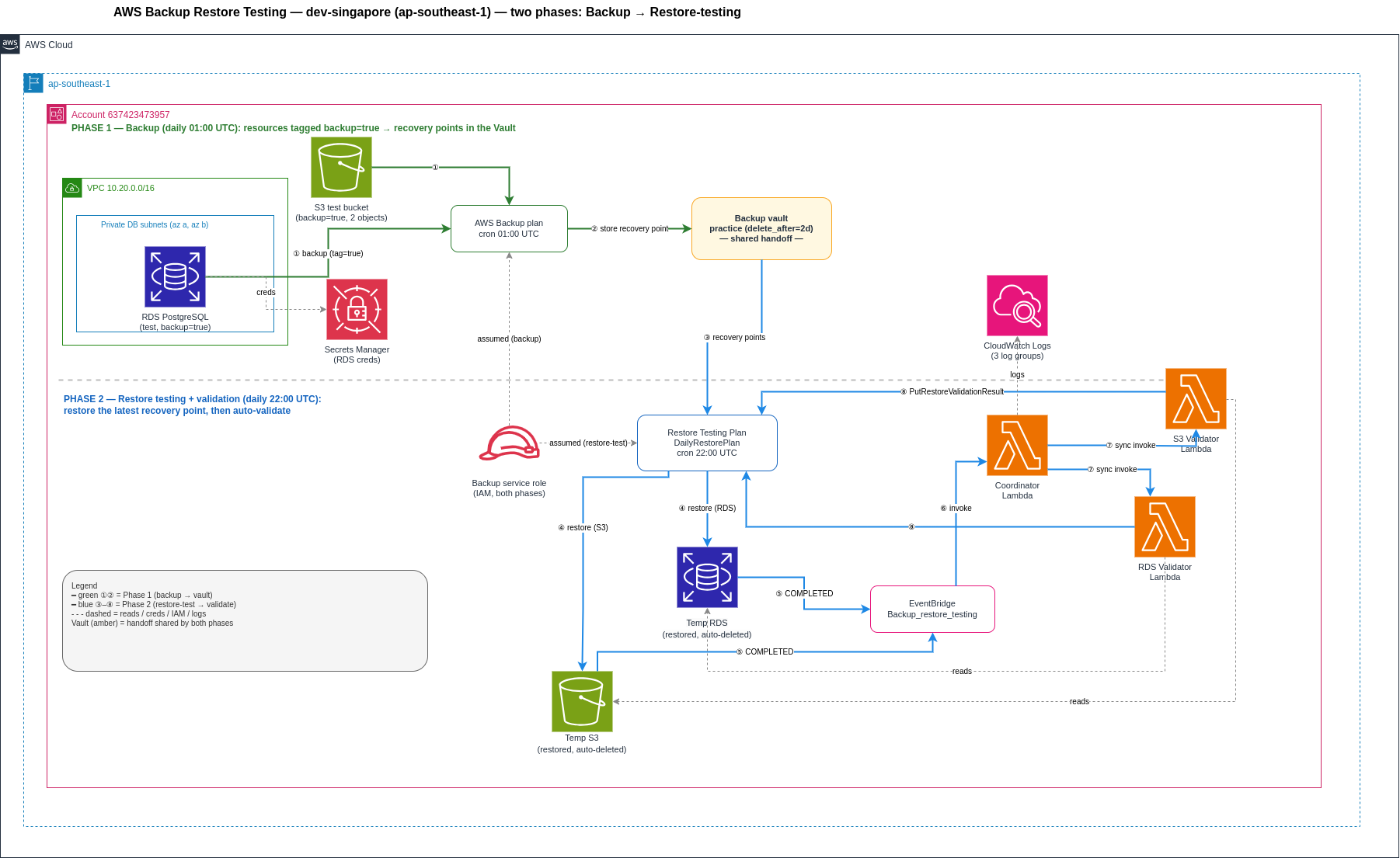
Phase 1 — Backup (nightly 01:00 UTC)
A backup plan runs on schedule and picks up every resource tagged backup=true — in this lab, an RDS PostgreSQL instance and an S3 bucket. It creates recovery points and stores them in the vault. The tag is the contract: attach backup=true to any resource and it automatically enters the backup cycle. No explicit ARN list required.
Phase 2 — Restore Testing + Validation (nightly 22:00 UTC)
The restore testing plan pulls the most recent recovery point from the vault (within a 7-day selection window) and kicks off a restore to a temporary copy of the resource. AWS Backup manages that copy entirely — it is never part of any IaC state. When the restore job finishes, the following sequence executes:
- AWS Backup fires an EventBridge event:
Restore Job State Change / COMPLETED - An EventBridge rule (scoped to this plan’s ARN) invokes a Coordinator Lambda
- The Coordinator reads
resourceTypefrom the event and routes to the appropriate Validator Lambda — one for S3, one for RDS - The Validator checks the temporary resource:
- S3: confirms
object_count > 1(the lab bucket is pre-seeded with two objects) - RDS: confirms
DBInstanceStatus == "available"
- S3: confirms
- The Validator calls
backup:PutRestoreValidationResult—SUCCESSFULorFAILED - AWS Backup records the result, then auto-deletes the temporary copy after the 4-hour validation window closes
The outcome in the AWS Backup console: a dated pass/fail record for every recovery point tested. Nothing accumulates — AWS Backup owns the temporary resource lifecycle entirely.
Results & Evidence
The screenshots below show the system running end-to-end in a live AWS account ( ap-southeast-1). Each view corresponds to a specific claim made in the Architecture section above.
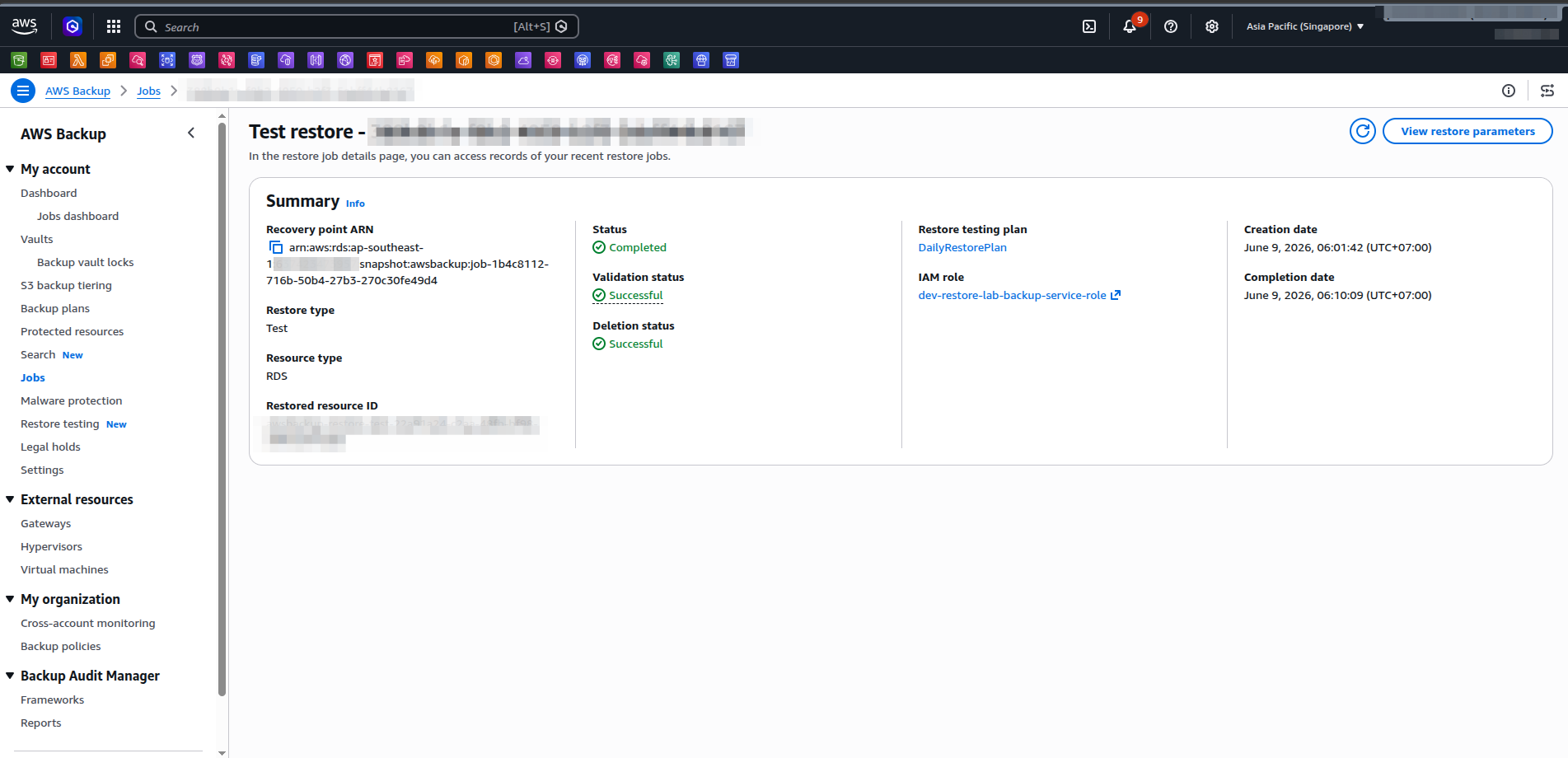
The most important screen is the restore job detail. Look at the three status fields in the Summary panel: Status = Completed means the restore itself succeeded; Validation status = Successful means the Coordinator Lambda routed correctly and the RDS validator confirmed the instance was available; Deletion status = Successful means AWS Backup cleaned up the temporary copy automatically — no manual teardown needed.
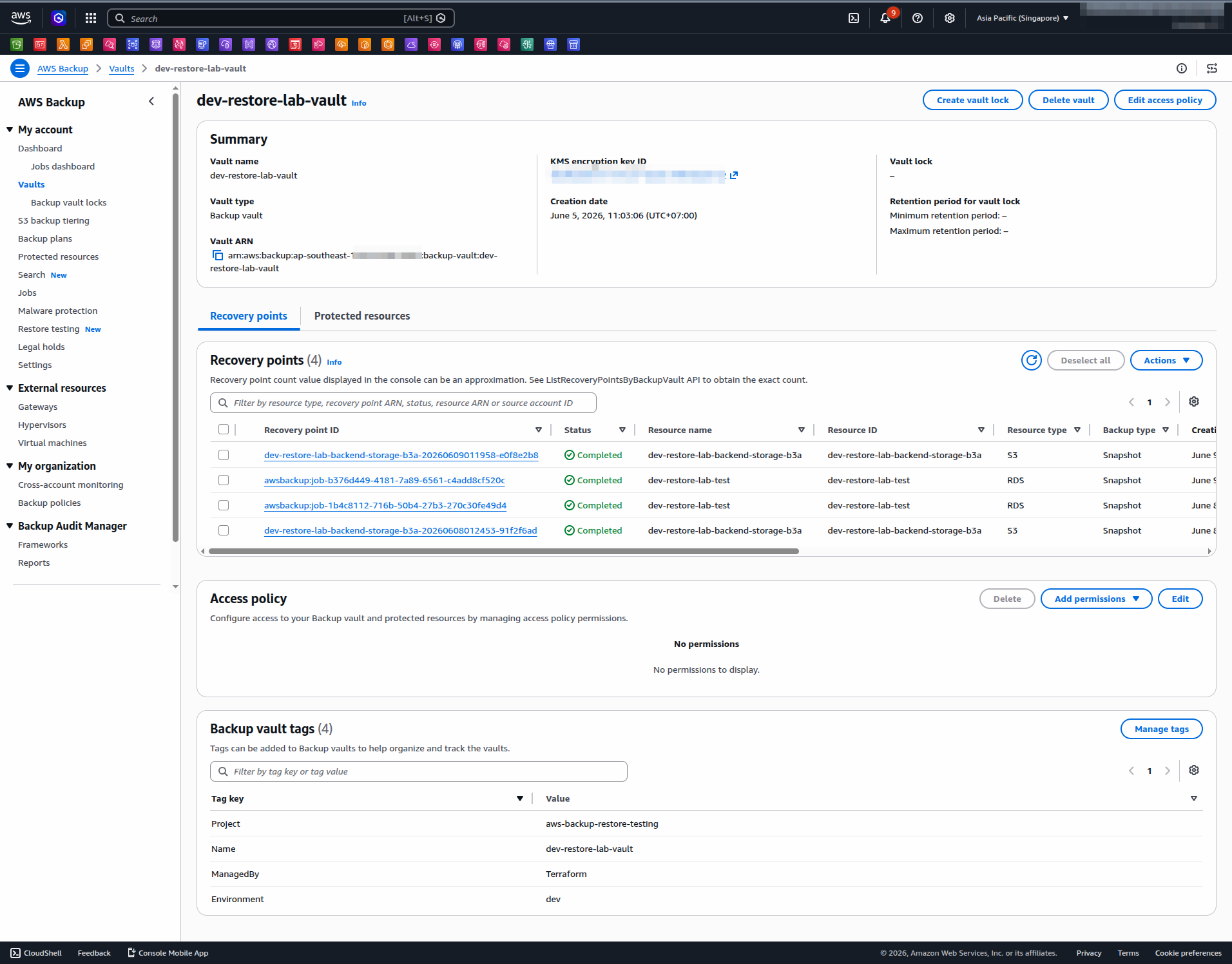
The vault view shows what Phase 1 produces. Each row in the Recovery points tab is a nightly snapshot — notice all statuses are Completed and the timestamps align with the 01:00 UTC schedule. This is the input that Phase 2 pulls from; without consistent recovery points here, the restore testing plan has nothing to test.
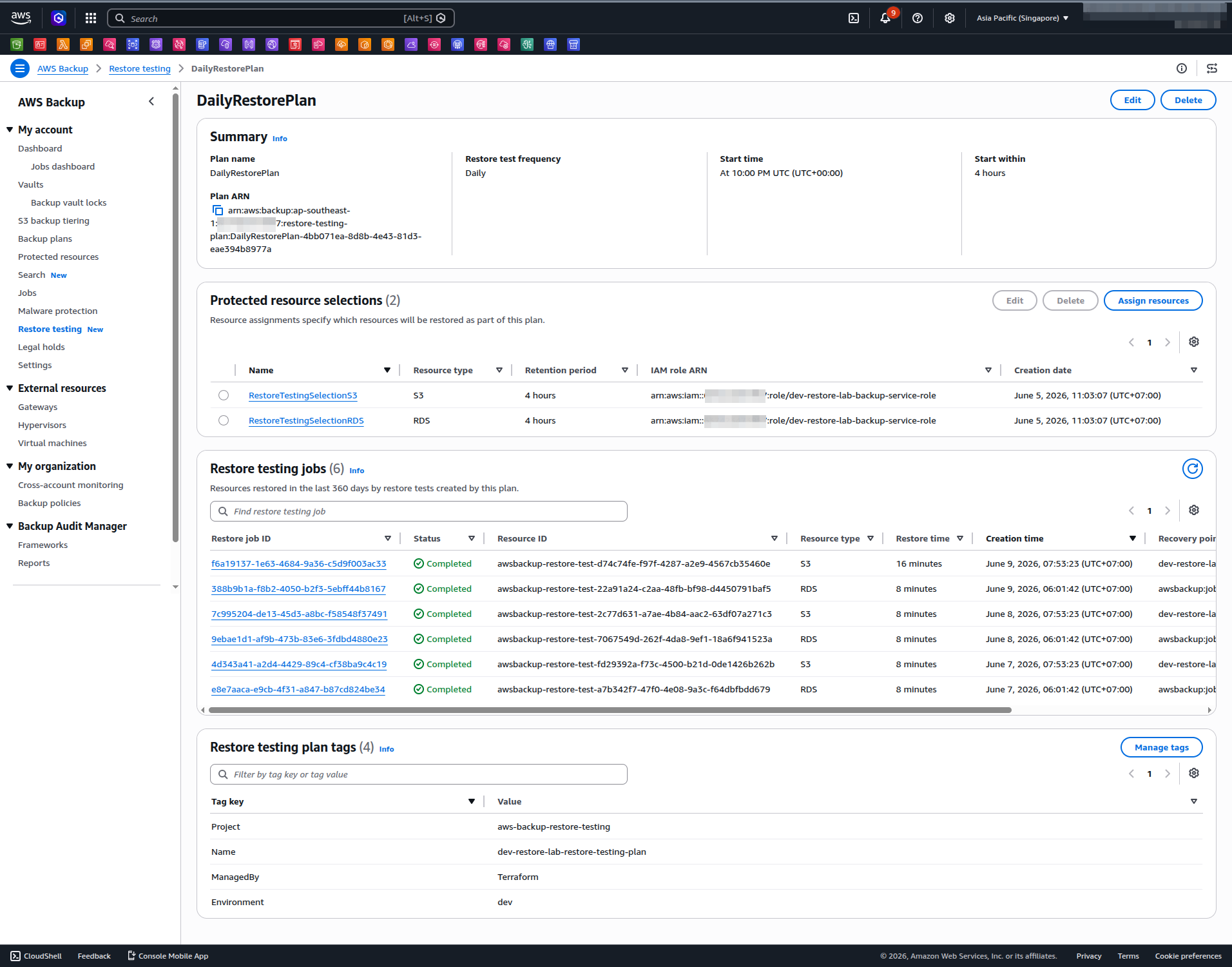
The restore testing plan page ties everything together. The top section shows the schedule and the 4-hour validation window. The Protected resource selections confirm both RDS and S3 are enrolled. The Restore testing jobs table at the bottom is the audit trail — each row is a dated test run with its outcome, exactly the evidence a compliance auditor would ask for.
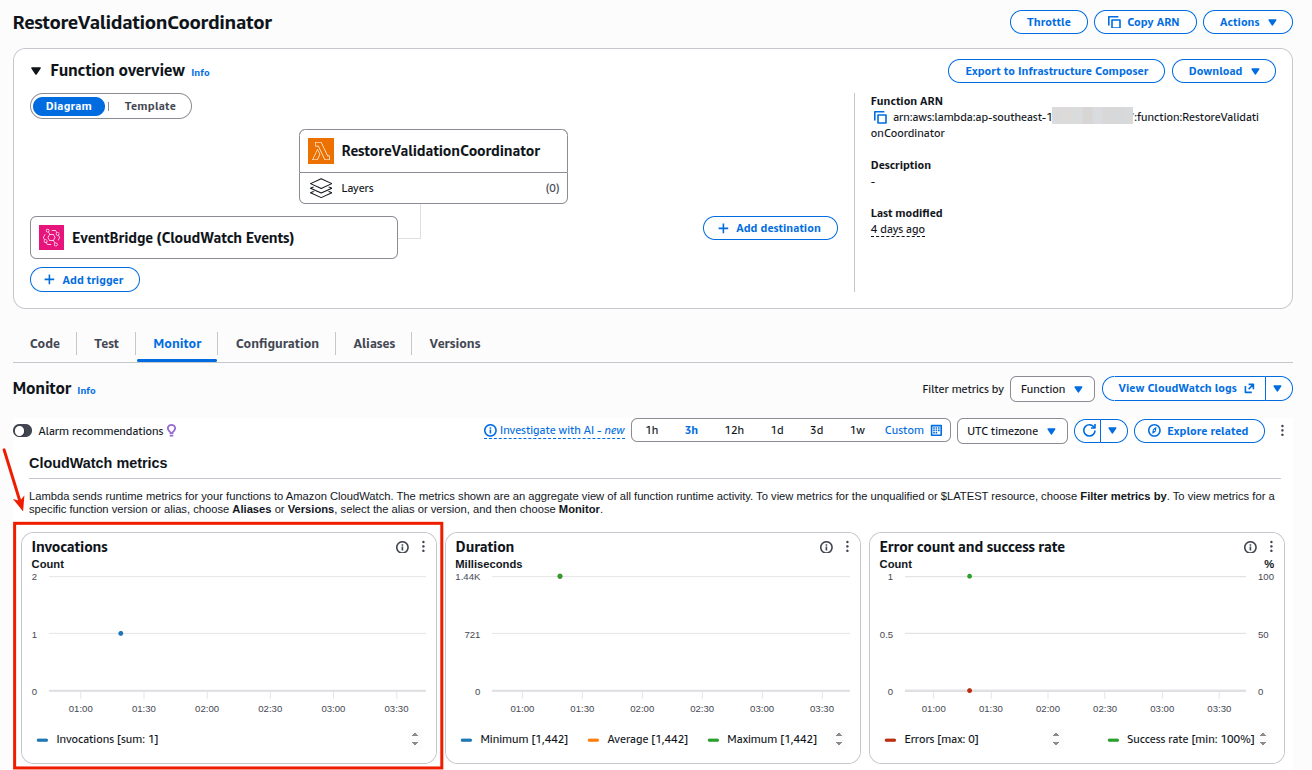
Finally, the Lambda Monitor tab confirms the EventBridge wiring is correct. The invocation spikes align with restore job completion events — the Coordinator was triggered at exactly the right moment. Zero errors in the Error count panel means every invocation produced a result, and the 1.44 s average duration is well within the 4-hour validation window.
Design Decisions
Coordinator + dedicated validators, not a single branching Lambda
A single Lambda that branches on resource type works fine for two types. It breaks down when you add a third — you’re touching existing logic to add new capability. The coordinator pattern inverts this: the coordinator routes, each validator owns its own resource type. Adding EFS or DynamoDB support means writing one new function, not modifying existing ones.
7-day recovery point selection window
The window is set to match the backup retention period. This ensures the plan always has a recent point available to test. A shorter window risks a silent skip: if last night’s backup failed and the window is only 24 hours, the restore testing plan finds no eligible recovery point and moves on — no FAILED result, no alert. Monitor for missing results, not just failures.
4-hour validation window
AWS Backup keeps the temporary restored resource alive for 4 hours after the restore completes. The window is fixed by the service — submitting a result early does not shorten it. If no result arrives within 4 hours, the job status becomes TIMED_OUT, not FAILED. These are different failure modes requiring different investigations.
EventBridge rule scoped to this plan's ARN
Without a restoreTestingPlanArnfilter in the event pattern, manual restores and restores from other plans in the same account trigger the same validation pipeline. Scoping the rule to this plan’s ARN prevents false positives and makes the pipeline predictable.
Extended Knowledge
“Recovery point created” ≠ “recovery point restorable”
This is the core insight the entire pattern is built on. AWS Backup evaluates whether a recovery point can actually restore only at restore time — not at backup time. A backup job completes successfully when the recovery point is created and stored. It says nothing about what happens when you try to use it.
The failure modes that surface during restore — subnet group deleted, IAM role permission removed, KMS key disabled, service quota exceeded — leave no trace in the backup job logs. They only reveal themselves when you attempt a restore. Automated restore testing is the only mechanism that catches these before an incident forces your hand.
TIMED_OUT is about your pipeline, not your backup
When a restore testing job shows ValidationStatus = TIMED_OUT, the natural instinct is to investigate the backup. Resist it. TIMED_OUT means the validator never submitted a result within the 4-hour window — the backup itself likely restored fine.
The right first step is CloudWatch Logs for the Coordinator and Validator Lambda functions. Common causes:
- EventBridge rule not matching — wrong field name in the event pattern (see Takeaway #3)
- Lambda missing an
InvokeFunctionpermission from the rule - Coordinator routing to an incorrect function name
- Validator IAM policy using the wrong S3 bucket prefix — it must be
awsbackup-restore-*
Pro tip
ValidationStatus = TIMED_OUT results in addition to FAILED. A pipeline that silently times out every night provides zero DR assurance while your backup console stays green.Compliance value: proof, not just policy
A backup policy document tells an auditor what you intend to do. Restore testing results tell them what you actually did. The difference matters when regulators ask for evidence rather than statements.
| Framework | Requirement | What restore testing provides |
|---|---|---|
| SOC 2 CC9.1 | Risk mitigation controls | Dated, automated pass/fail records per resource |
| ISO 27001 A.17.1.3 | Verify backups regularly | Scheduled automated testing satisfies "regular verification" |
| NYDFS §500.16 | Backup and recovery | Audit trail in Backup console + CloudWatch Logs |
| EU DORA Art. 12 | ICT backup testing | Continuous evidence of restore capability |
AWS Backup Audit Manager can generate compliance reports directly from restore testing results, aggregated across accounts and time periods — a ready-made audit package when the evidence request arrives.
The real cost of “free” restore testing
Restore testing is not free — each run spins up real compute. In this lab (ap-southeast-1, db.t4g.micro):
| Item | Config | Est./month |
|---|---|---|
| Source RDS (always-on) | db.t4g.micro, 20 GB gp3 | ~$11–14 |
| Daily restore runs | 1 temp instance × ~4h/day | ~$2–4 |
| Backup storage | RDS + S3, 2-day retention | ~$1–2 |
| Lambda, CloudWatch, S3 | Low volume | ~$0–1 |
| Total | ~$15–22/month |
For production workloads, this cost is trivial relative to the assurance it provides. For a lab, destroy the environment between sessions. Running S3-only mode (no RDS) saves ~$15/month while still exercising the full EventBridge → Lambda → validation pipeline.
Security & Cost Posture
Security highlights
- RDS master password auto-generated and stored in Secrets Manager — never written to config or IaC state
- RDS is private: no public endpoint, database-subnet placement, security group with egress deny-all
- S3 bucket: server-side encryption, public access fully blocked, versioning enabled
- Backup vault encrypted with AWS-managed KMS
- Lambda IAM roles scoped by function: the Coordinator can only invoke the two Validator functions; each Validator can only describe or list its own resource type
Cost controls
Use S3-only mode when practicing the validation pipeline — it eliminates the always-on RDS instance and drops the monthly cost by ~$15 while keeping the full EventBridge → Lambda → validation flow intact. Destroy the complete environment after each lab session to avoid accumulating the ~$15–22/month ongoing cost.
Takeaways
- Backup job success is not proof of recoverability. A recovery point that restores reliably today might fail tomorrow if infrastructure around it changes. Continuous automated restore testing is the only signal that tracks this.
TIMED_OUTmeans your validation pipeline broke, not your backup. Check Lambda CloudWatch Logs first — the restore itself probably completed fine.- Use
detail.status, notdetail.state. AWS Backup events differ from EC2. Getting this field name wrong produces a silent rule that never fires — no errors, no matches, no results. - AWS names restored S3 buckets
awsbackup-restore-*. Scope IAM policies to this exact prefix — the wrong prefix causes silentAccessDeniedandTIMED_OUT. - Tag-based selection requires tag governance. Missing a
backup=truetag means silent exclusion from the backup cycle. Enforce tags at the account level, not as a convention. - The coordinator pattern pays for itself when you add a second resource type. Routing logic and validation logic should never live in the same function.